

Neural characters language models
We’ve checked out statistical approaches to language models in the last post. Now let’s go find out what deep learning has to offer.

We’re gonna use the same dataset as before, except this time we build a language model that’s character-level, not word level. Before you go:
- The data can be downloaded on Kaggle.
- This project uses TensorFlow v2.0: this is how you install it; and that’s how you use it.
This post is inspired by a homework from the course NLP For You.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
Working on character level means that we don’t need to deal with large vocabulary or missing words. Heck, we can even keep uppercase words in text! The downside, however, is that all our sequences just got a lot longer.
However, we still need special tokens:
- Begin Of Sequence (BOS) - this token is at the start of each sequence. We use it so that we always have non-empty input to our neural network.
- End Of Sequence (EOS) - you guess it… this token is at the end of each sequence. The catch is that it should not occur anywhere else except at the very end. If our model produces this token, the sequence is over.
BOS, EOS = ' ', '\n'
data = pd.read_json("./arxivData.json")
lines = data.apply(lambda row: (row['title'] + ' ; ' + row['summary'])[:512], axis=1) \
.apply(lambda line: BOS + line.replace(EOS, ' ') + EOS) \
.tolist()
# Download data here - https://yadi.sk/d/_nGyU2IajjR9-w
Our next step is building char-level vocabulary. Put simply, you need to assemble a list of all unique tokens in the dataset.
# get all unique characters from lines (including capital letters and symbols)
tokens = list(set(list(' '.join(lines))))
tokens = sorted(tokens)
n_tokens = len(tokens)
print ('n_tokens = ',n_tokens)
assert 100 < n_tokens < 150
assert BOS in tokens, EOS in tokens
n_tokens = 136
We can now assign each character with it’s index in tokens list. This way we can encode a string into a TF-friendly integer vector.
# dictionary of character -> its identifier (index in tokens list)
token_to_id = { c : i for i,c in enumerate(tokens)}
assert len(tokens) == len(token_to_id), "dictionaries must have same size"
for i in range(n_tokens):
assert token_to_id[tokens[i]] == i, "token identifier must be it's position in tokens list"
print("Seems alright!")
Our final step is to assemble several strings in a integet matrix [batch_size, text_length].
The only problem is that each sequence has a different length. We can work around that by padding short sequences with extra EOS or cropping long sequences. Here’s how it works:
def to_matrix(lines, max_len=None, pad=token_to_id[EOS], dtype='int32'):
"""Casts a list of lines into tf-digestable matrix"""
max_len = max_len or max(map(len, lines))
lines_ix = np.full([len(lines), max_len], pad, dtype=dtype)
for i in range(len(lines)):
line_ix = list(map(token_to_id.get, lines[i][:max_len]))
lines_ix[i, :len(line_ix)] = line_ix
return lines_ix
#Example: cast 4 random names to matrices, pad with zeros
dummy_lines = [
' abc\n',
' abacaba\n',
' abc1234567890\n',
]
print(to_matrix(dummy_lines))
[[ 1 66 67 68 0 0 0 0 0 0 0 0 0 0 0]
[ 1 66 67 66 68 66 67 66 0 0 0 0 0 0 0]
[ 1 66 67 68 18 19 20 21 22 23 24 25 26 17 0]]
Neural Language Model
Just like for N-gram LMs, we want to estimate probability of text as a joint probability of tokens (symbols this time).
\[P(X) = \prod_t P(x_t \mid x_0, \dots, x_{t-1}).\]Instead of counting all possible statistics, we want to train a neural network with parameters $\theta$ that estimates the conditional probabilities:
\[P(x_t \mid x_0, \dots, x_{t-1}) \approx p(x_t \mid x_0, \dots, x_{t-1}, \theta)\]But before we optimize, we need to define our neural network. Let’s start with a fixed-window (aka convolutional) architecture:
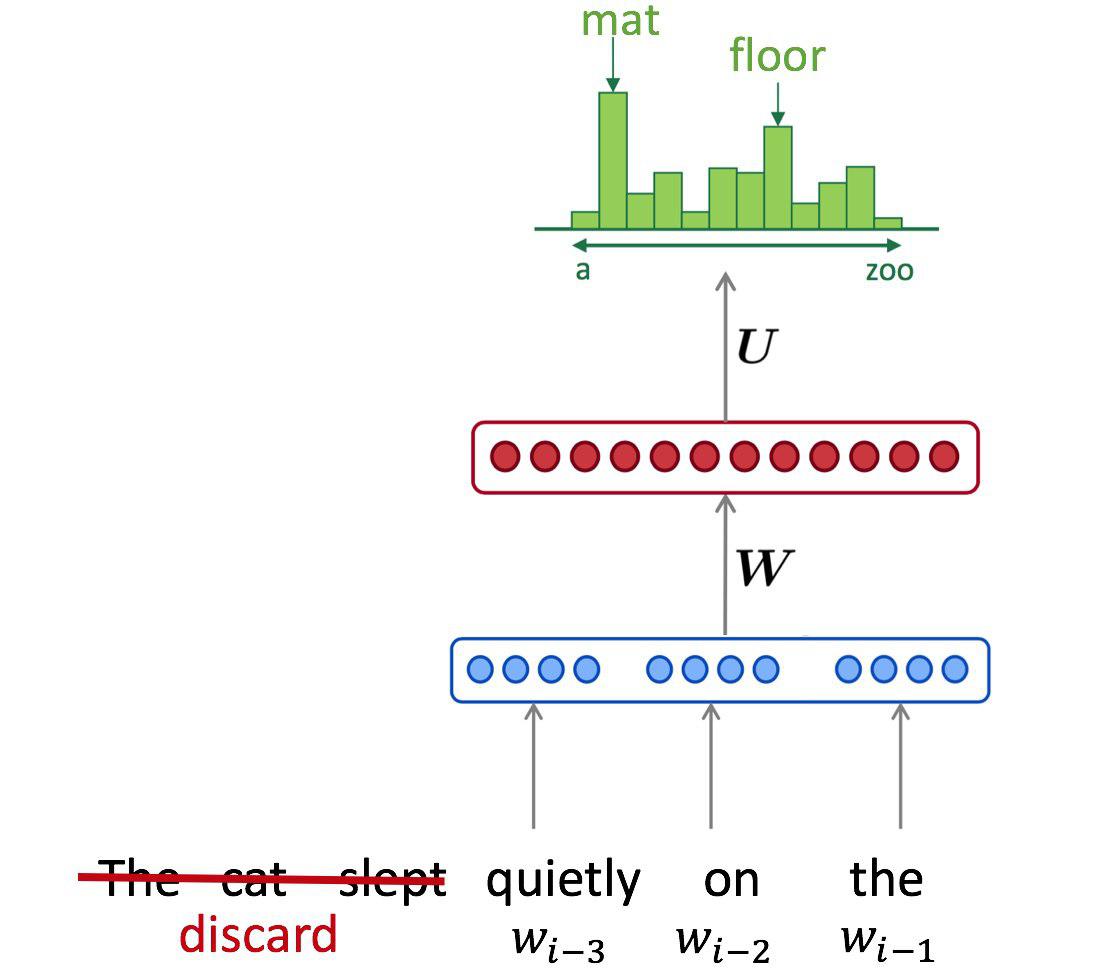
import tensorflow as tf
keras, L = tf.keras, tf.keras.layers
assert tf.__version__.startswith('2'), "Current tf version: {}; required: 2.0.*".format(tf.__version__)
class FixedWindowLanguageModel(L.Layer):
def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=64):
"""
A fixed window model that looks on at least 5 previous symbols.
Note: fixed window LM is effectively performing a convolution over a sequence of words.
This convolution only looks on current and previous words.
Such convolution can be represented as a sequence of 2 operations:
- pad input vectors by {strides * (filter_size - 1)} zero vectors on the "left", do not pad right
- perform regular convolution with {filter_size} and {strides}
- If you're absolutely lost, here's a hint: use ZeroPadding1D and Conv1D from keras.layers
You can stack several convolutions at once
"""
super().__init__() # initialize base class to track sub-layers, trainable variables, etc.
#create layers/variables and any metadata you want, e.g. self.emb = L.Embedding(...)
strides = 1
#filter_size = 16
filter_size = 32
kernel_size = 5
self.emb = L.Embedding(n_tokens, emb_size)
self.pad = L.ZeroPadding1D(padding = (strides*(kernel_size-1), 0))
self.conv = L.Conv1D(filters=filter_size, kernel_size=kernel_size, strides = strides, padding="valid", activation='relu')
self.dense = L.Dense(n_tokens)
def __call__(self, input_ix):
"""
compute language model logits given input tokens
:param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]
:returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]
these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})
"""
# apply layers, see docstring above
x = self.emb(input_ix)
x = self.pad(x)
x = self.conv(x)
x = self.pad(x)
x = self.conv(x)
x = self.pad(x)
x = self.conv(x)
x = self.pad(x)
x = self.conv(x)
return self.dense(x)
def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100):
""" :returns: probabilities of next token, dict {token : prob} for all tokens """
prefix_ix = tf.convert_to_tensor(to_matrix([prefix]), tf.int32)
probs = tf.nn.softmax(self(prefix_ix)[0, -1]).numpy() # shape: [n_tokens]
return dict(zip(tokens, probs))
model = FixedWindowLanguageModel()
# note: tensorflow and keras layers create variables only after they're first applied (called)
dummy_input_ix = tf.constant(to_matrix(dummy_lines))
dummy_logits = model(dummy_input_ix)
print('Weights:', tuple(w.name for w in model.trainable_variables))
#dummy_input_ix.shape
dummy_logits.shape
(len(dummy_lines), max(map(len, dummy_lines)), n_tokens)
assert isinstance(dummy_logits, tf.Tensor)
assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), "please check output shape"
assert np.all(np.isfinite(dummy_logits)), "inf/nan encountered"
assert not np.allclose(dummy_logits.numpy().sum(-1), 1), "please predict linear outputs, don't use softmax (maybe you've just got unlucky)"
# test for lookahead
dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))
dummy_logits_2 = model(dummy_input_ix_2)
assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), "your model's predictions depend on FUTURE tokens. " \
" Make sure you don't allow any layers to look ahead of current token." \
" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test."
We can now tune our network’s parameters to minimize categorical crossentropy over training dataset \(D\):
\[L = {\frac1{|D|}} \sum_{X \in D} \sum_{x_i \in X} - \log p(x_t \mid x_1, \dots, x_{t-1}, \theta)\]As usual with with neural nets, this optimization is performed via stochastic gradient descent with backprop. One can also note that minimizing crossentropy is equivalent to minimizing model perplexity, KL-divergence or maximizng log-likelihood.
def compute_lengths(input_ix, eos_ix=token_to_id[EOS]):
""" compute length of each line in input ix (incl. first EOS), int32 vector of shape [batch_size] """
count_eos = tf.cumsum(tf.cast(tf.equal(input_ix, eos_ix), tf.int32), axis=1, exclusive=True)
lengths = tf.reduce_sum(tf.cast(tf.equal(count_eos, 0), tf.int32), axis=1)
return lengths
print('matrix:\n', dummy_input_ix.numpy())
print('lengths:', compute_lengths(dummy_input_ix).numpy())
def compute_loss(model, input_ix):
"""
:param model: language model that can compute next token logits given token indices
:param input ix: int32 matrix of tokens, shape: [batch_size, length]; padded with eos_ix
"""
input_ix = tf.convert_to_tensor(input_ix, dtype=tf.int32)
logits = model(input_ix[:, :-1])
reference_answers = input_ix[:, 1:]
# Your task: implement loss function as per formula above
# your loss should only be computed on actual tokens, excluding padding
# predicting actual tokens and first EOS do count. Subsequent EOS-es don't
# you will likely need to use compute_lengths and/or tf.sequence_mask to get it right.
lengths = compute_lengths(input_ix[:, :-1])
mask = tf.sequence_mask(lengths, maxlen = input_ix.shape.as_list()[1] -1, dtype = tf.float32)
#<return scalar loss>
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = reference_answers, logits = logits)
loss *= mask
return tf.reduce_sum(loss)/tf.cast(tf.reduce_sum(lengths), tf.float32)
loss_1 = compute_loss(model, to_matrix(dummy_lines, max_len=16))
loss_2 = compute_loss(model, to_matrix(dummy_lines, max_len=17))
assert (np.ndim(loss_1) == 0) and (0 < loss_1 < 100), "loss must be a positive scalar"
assert np.allclose(loss_1, loss_2), 'do not include AFTER first EOS into loss. '\
'Hint: use tf.sequence_mask. Beware +/-1 errors. And be careful when averaging!'
Evaluation
You will need two functions: one to compute test loss and another to generate samples. For your convenience, we implemented them both in your stead.
def score_lines(model, dev_lines, batch_size):
""" computes average loss over the entire dataset """
dev_loss_num, dev_loss_len = 0., 0.
for i in range(0, len(dev_lines), batch_size):
batch_ix = to_matrix(dev_lines[i: i + batch_size])
dev_loss_num += compute_loss(model, batch_ix) * len(batch_ix)
dev_loss_len += len(batch_ix)
return dev_loss_num / dev_loss_len
def generate(model, prefix=BOS, temperature=1.0, max_len=100):
"""
Samples output sequence from probability distribution obtained by model
:param temperature: samples proportionally to model probabilities ^ temperature
if temperature == 0, always takes most likely token. Break ties arbitrarily.
"""
while True:
token_probs = model.get_possible_next_tokens(prefix)
tokens, probs = zip(*token_probs.items())
if temperature == 0:
next_token = tokens[np.argmax(probs)]
else:
probs = np.array([p ** (1. / temperature) for p in probs])
probs /= sum(probs)
next_token = np.random.choice(tokens, p=probs)
prefix += next_token
if next_token == EOS or len(prefix) > max_len: break
return prefix
Training loop
Finally, let’s train our model on minibatches of data
from sklearn.model_selection import train_test_split
train_lines, dev_lines = train_test_split(lines, test_size=0.25, random_state=42)
batch_size = 256
score_dev_every = 250
train_history, dev_history = [], []
optimizer = keras.optimizers.Adam()
# score untrained model
dev_history.append((0, score_lines(model, dev_lines, batch_size)))
print("Sample before training:", generate(model, 'Bridging'))
from IPython.display import clear_output
from random import sample
from tqdm import trange
for i in trange(len(train_history), 5000):
batch = to_matrix(sample(train_lines, batch_size))
with tf.GradientTape() as tape:
loss_i = compute_loss(model, batch)
grads = tape.gradient(loss_i, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_history.append((i, loss_i.numpy()))
if (i + 1) % 50 == 0:
clear_output(True)
plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')
if len(dev_history):
plt.plot(*zip(*dev_history), color='red', label='dev_loss')
plt.legend(); plt.grid(); plt.show()
print("Generated examples (tau=0.5):")
for _ in range(3):
print(generate(model, temperature=0.5))
if (i + 1) % score_dev_every == 0:
print("Scoring dev...")
dev_history.append((i, score_lines(model, dev_lines, batch_size)))
print('#%i Dev loss: %.3f' % dev_history[-1])
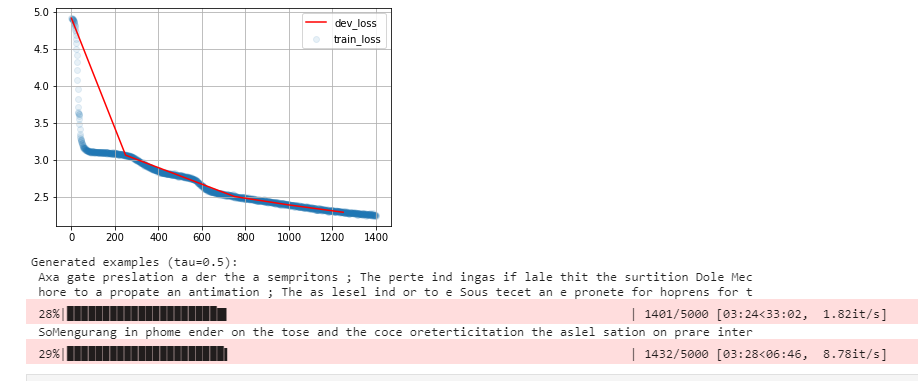
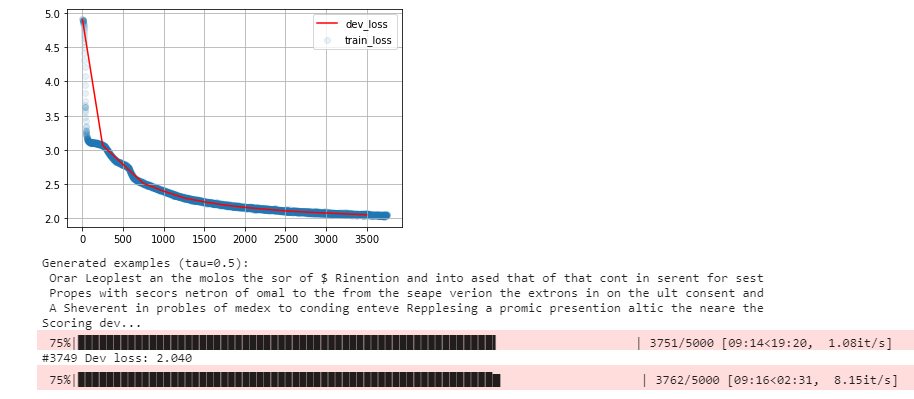
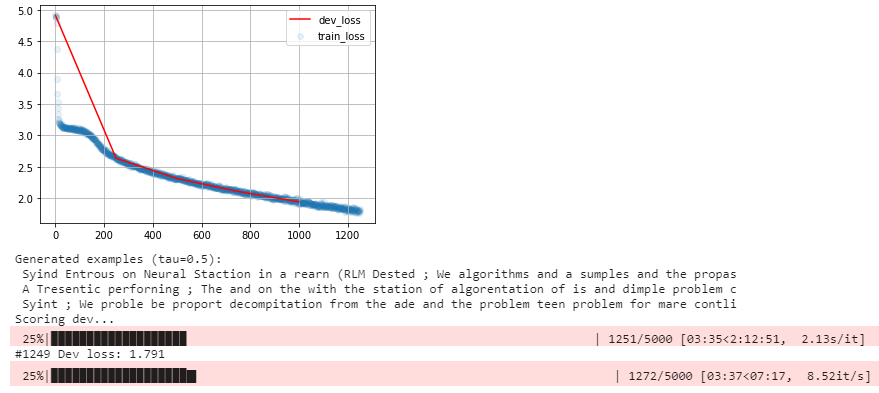
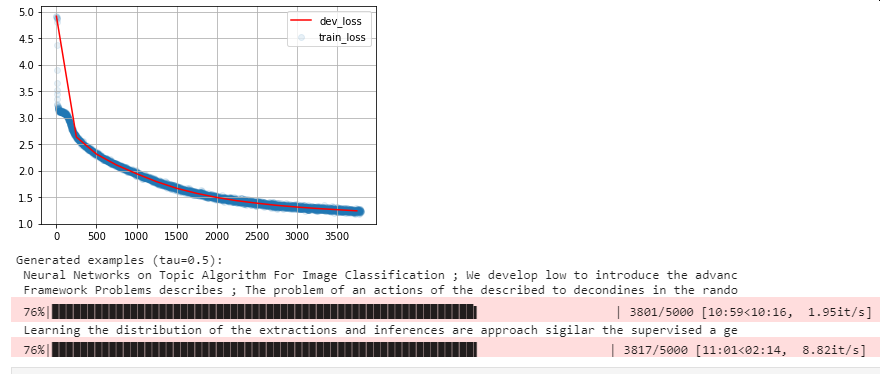
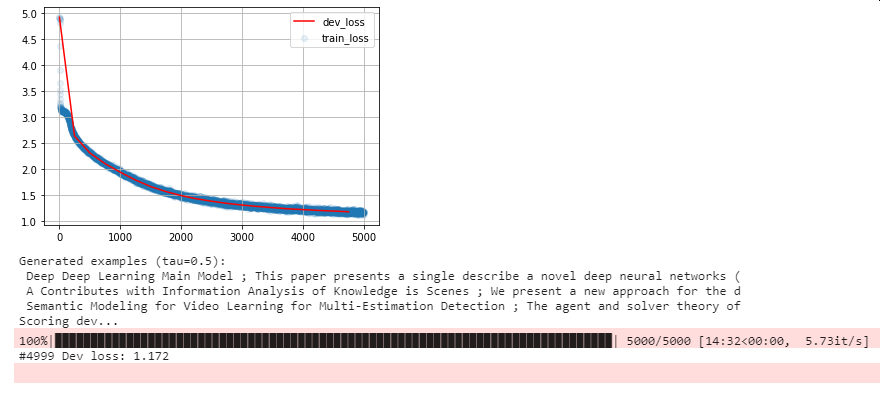
Here are some outputs from the training process:
- At 28%:
- At 75%:
- At 100%:
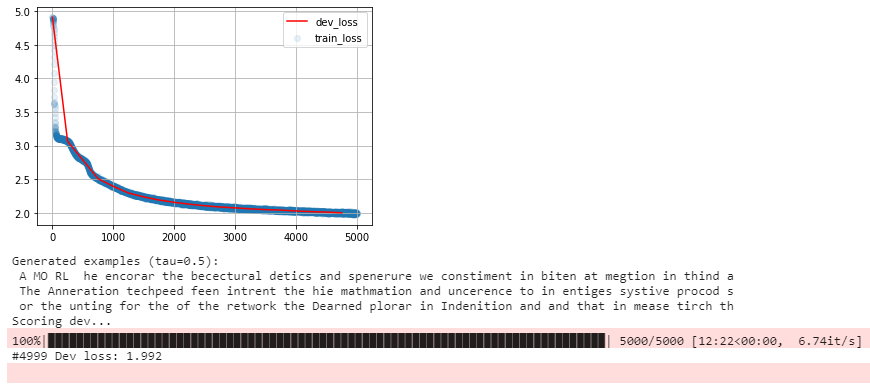
We see the improvements in the generated text during the training process.
assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], "The model didn't converge."
print("Final dev loss:", dev_history[-1][-1])
for i in range(10):
print(generate(model, temperature=0.5))
Final dev loss: tf.Tensor(1.9916248, shape=(), dtype=float32)
Corfertive bich the sear asting for the the extend of the propoctien is desent the prover and the th
In this the constres of the compution and of the a the that neals and and provese the on at mation a
A the continting of a devising as orterd of this propertem and assod tisting and of entione a denel
Sy DES) to procods nor and and and a teut detrion and and porerach from sesting proves and tu the re
The CAnstwisk and stow the retricullact and intation at entlistic that in the intrace the camation o
or extrons ; In exlllent nears ; The exbectlosition the porsention this in the the and candes of tra
The Coustring ; This in the proved as from the orveric work with the a network which anstrocion to t
Herents reproce in and has in that as a datic problem and conaliges unting is the the searling datio
A coxestion and rensent macheution of the reilic propering bethtieg of concon and mather model the p
A Shose we weis a proprome and learning and that sor as a she approal and as an of feature the menti
This is not so bad but there are still a lot words that don’t mean anything. Can we improve this using a RNN type neural network?
RNN Language Models
Fixed-size architectures are reasonably good when capturing short-term dependencies, but their design prevents them from capturing any signal outside their window. We can mitigate this problem by using a recurrent neural network:
\[h_0 = \vec 0 ; \quad h_{t+1} = RNN(x_t, h_t)\] \[p(x_t \mid x_0, \dots, x_{t-1}, \theta) = dense_{softmax}(h_{t-1})\]Such model processes one token at a time, left to right, and maintains a hidden state vector between them. Theoretically, it can learn arbitrarily long temporal dependencies given large enough hidden size.
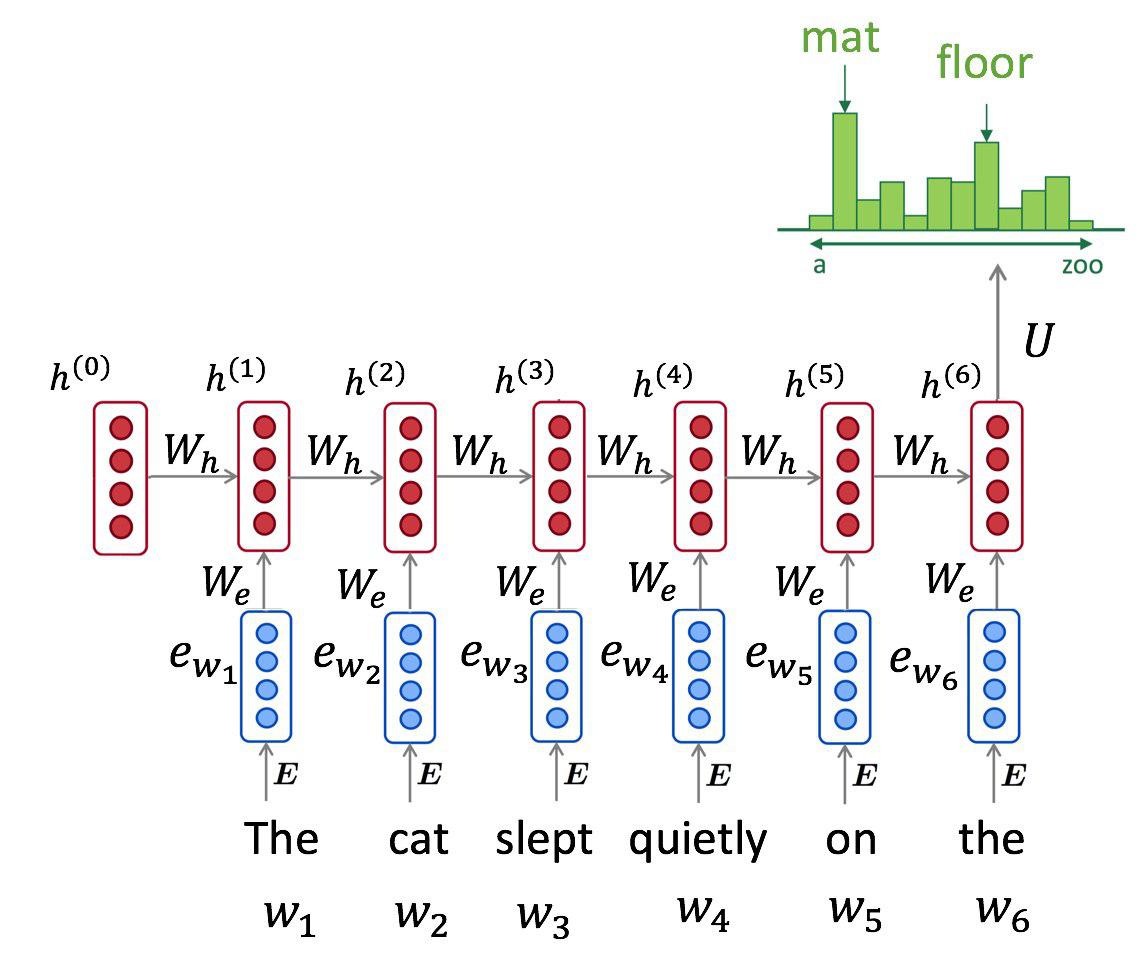
class RNNLanguageModel(L.Layer):
def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=256):
"""
Build a recurrent language model.
You are free to choose anything you want, but the recommended architecture is
- token embeddings
- one or more LSTM/GRU layers with hid size
- linear layer to predict logits
"""
super().__init__() # initialize base class to track sub-layers, trainable variables, etc.
# create layers/variables/etc
self.emb = L.Embedding(n_tokens, emb_size)
self.LSTM = L.LSTM(hid_size, return_sequences=True)
self.dense = L.Dense(n_tokens)
def __call__(self, input_ix):
"""
compute language model logits given input tokens
:param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]
:returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]
these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})
"""
x = self.emb(input_ix)
x = self.LSTM(x)
return self.dense(x)
def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100):
""" :returns: probabilities of next token, dict {token : prob} for all tokens """
prefix_ix = tf.convert_to_tensor(to_matrix([prefix]), tf.int32)
probs = tf.nn.softmax(self(prefix_ix)[0, -1]).numpy() # shape: [n_tokens]
return dict(zip(tokens, probs))
model = RNNLanguageModel()
# note: tensorflow and keras layers create variables only after they're first applied (called)
dummy_input_ix = tf.constant(to_matrix(dummy_lines))
dummy_logits = model(dummy_input_ix)
assert isinstance(dummy_logits, tf.Tensor)
assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), "please check output shape"
assert np.all(np.isfinite(dummy_logits)), "inf/nan encountered"
assert not np.allclose(dummy_logits.numpy().sum(-1), 1), "please predict linear outputs, don't use softmax (maybe you've just got unlucky)"
print('Weights:', tuple(w.name for w in model.trainable_variables))
# test for lookahead
dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))
dummy_logits_2 = model(dummy_input_ix_2)
assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), "your model's predictions depend on FUTURE tokens. " \
" Make sure you don't allow any layers to look ahead of current token." \
" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test."
RNN training
Our RNN language model should optimize the same loss function as fixed-window model. But there’s a catch. Since RNN recurrently multiplies gradients through many time-steps, gradient values may explode, ruining your model. The common solution to that problem is to clip gradients either individually or globally.
{kind=link}
Your task here is to prepare tensorflow graph that would minimize the same loss function. If you encounter large loss fluctuations during training, please add gradient clipping using urls above.
Note: gradient clipping is not exclusive to RNNs. Convolutional networks with enough depth often suffer from the same issue.
batch_size = 64 # <-- please tune batch size to fit your CPU/GPU configuration
score_dev_every = 250
train_history, dev_history = [], []
optimizer = keras.optimizers.Adam()
# score untrained model
dev_history.append((0, score_lines(model, dev_lines, batch_size)))
print("Sample before training:", generate(model, 'Bridging'))
for i in trange(len(train_history), 5000):
batch = to_matrix(sample(train_lines, batch_size))
with tf.GradientTape() as tape:
loss_i = compute_loss(model, batch)
grads = tape.gradient(loss_i, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_history.append((i, loss_i.numpy()))
if (i + 1) % 50 == 0:
clear_output(True)
plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')
if len(dev_history):
plt.plot(*zip(*dev_history), color='red', label='dev_loss')
plt.legend(); plt.grid(); plt.show()
print("Generated examples (tau=0.5):")
for _ in range(3):
print(generate(model, temperature=0.5))
if (i + 1) % score_dev_every == 0:
print("Scoring dev...")
dev_history.append((i, score_lines(model, dev_lines, batch_size)))
print('#%i Dev loss: %.3f' % dev_history[-1])
Here are some outputs from the training process:
- At 28%:
- At 75%:
- At 100%:
assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], "The model didn't converge."
print("Final dev loss:", dev_history[-1][-1])
for i in range(10):
print(generate(model, temperature=0.5))
Final dev loss: tf.Tensor(1.1723021, shape=(), dtype=float32) A Fast States well Control Set ; The parailed spoces of the specifically, we propose a new problem a
Detection with Theoretic A Complete Robust Optimal Machine Learning ; In a semantic controlled and i
Automatic Complete Constraint Segmentation of State-of-the-are Linear Neural Networks ; In this pape
A Generalized Problem of Programming and Image Sequence Signal Binary Learning ; In this paper prese
A Particular Prediction Statistical Search Agent Subspace Recognition ; We introduce a non-linear en
A New Synthesis Detection for Subset Algorithm for Processes ; In this paper, we propose a new parti
On the Personal method An and Particular Component Analysis ; In this paper, we propose a novel assu
Explore Multi-Image Clustering Transformation ; We propose a new multi-limen discrete datasets is a
Full Control Recognition of Stationarization ; We analyze the structure of different task of a syste
The Sparse Learning Networks for Relation ; This paper, we propose a novel and solution of an intere
Alternative sampling strategies
So far we’ve sampled tokens from the model in proportion with their probability. However, this approach can sometimes generate nonsense words due to the fact that softmax probabilities of these words are never exactly zero. This issue can be somewhat mitigated with sampling temperature, but low temperature harms sampling diversity. Can we remove the nonsense words without sacrificing diversity? Yes, we can! But it takes a different sampling strategy.
Top-k sampling: on each step, sample the next token from k most likely candidates from the language model.
Suppose \(k=3\) and the token probabilities are \(p=[0.1, 0.35, 0.05, 0.2, 0.3]\). You first need to select \(k\) most likely words and set the probability of the rest to zero: \(\hat p=[0.0, 0.35, 0.0, 0.2, 0.3]\) and re-normalize: \(p^*\approx[0.0, 0.412, 0.0, 0.235, 0.353]\).
Nucleus sampling: similar to top-k sampling, but this time we select \(k\) dynamically. In nucleous sampling, we sample from top-__N%__ fraction of the probability mass.
Using the same \(p=[0.1, 0.35, 0.05, 0.2, 0.3]\) and nucleous N=0.9, the nucleous words consist of:
- most likely token \(w_2\), because \(p(w_2) < N\)
- second most likely token \(w_5\), \(p(w_2) + p(w_5) = 0.65 < N\)
- third most likely token \(w_4\) because \(p(w_2) + p(w_5) + p(w_4) = 0.85 < N\)
And thats it, because the next most likely word would overflow: \(p(w_2) + p(w_5) + p(w_4) + p(w_1) = 0.95 > N\).
After you’ve selected the nucleous words, you need to re-normalize them as in top-k sampling and generate the next token.
Your task is to implement nucleus sampling variant and see if its any good.
def generate_nucleus(model, prefix=BOS, nucleus=0.9, max_len=100):
"""
Generate a sequence with nucleous sampling
:param prefix: a string containing space-separated previous tokens
:param nucleus: N from the formulae above, N \in [0, 1]
:param max_len: generate sequences with at most this many tokens, including prefix
:note: make sure that nucleous always contains at least one word, even if p(w*) > nucleus
"""
while True:
token_probs = model.get_possible_next_tokens(prefix)
tokens, probs = zip(*token_probs.items())
# l_probs: List to store the nucleus probabilities and keep the index
l_probs = list(probs)
# i_p: store the index of proba < nucleus
i_p = []
# Store nucleus probas only
probs_nuc = []
i_p.append(np.argmax(l_probs))
sum_probs = l_probs[i_p[0]]
while sum_probs < nucleus:
probs_nuc.append(l_probs[i_p[-1]])
# Remove the selected proba
l_probs[i_p[-1]] = 0.
i_p.append(np.argmax(l_probs))
sum_probs += l_probs[i_p[-1]]
sum_nuc = sum(probs_nuc)
l_probs= [0. for p in l_probs]
if len(i_p) > 1:
i_p = i_p[:-1]
l_probs = [probs[i] * (1./sum_nuc) if i in i_p else 0. for i,v in enumerate(l_probs) ]
else:
l_probs[i_p[0]] = 1.0
#next_token = tokens[np.argmax(l_probs)]
next_token = np.random.choice(tokens, p=l_probs)
prefix += next_token
if next_token == EOS or len(prefix) > max_len: break
return prefix
for i in range(10):
print(generate_nucleus(model, nucleus=0.90))
Online Lastigning An attention Models of Video ; Classifier in deep topic set of adaptive and exampl Pata-Similarity Criting of Approach for Semantics for Embed Learning ; In this work and use recent s Application of Stochastic Graphical Clustering Learning ; Attention tasks data for supervised method Comparing Information Arguted Analysis with Networks for Denistic Object Detection ; We propose a ne Modeling Graph Generative And Process for Frame Understand Deep Depresentation ; We propose a new pa Set of Hypasces ; Projection are use of cluster is a rarge of an improve parallel images of specific Robust the Sensing Reduction to Wemen and Stochastic Models ; In this paper introduced information i Object distinguished Set and interaction of the most for multi-labeling ; The temporal relations, a Increasing Neural Networks Multimally on Graphical Neural Networks ; Sensing a novel data which is a Ensuring Spatial Graph Visual Toop statistical Neural Networks ; The problem in understanding in var